

就在今天,DeepSeek 全新一代模型 V4 系列正式开源,并迅速冲上 Hugging Face 模型榜单首位。伴随模型开放,一份详尽的技术报告也同步公开,完整披露了该系列在硬件适配、架构改造、训练策略等环节的核心要点。无论从能力指标还是工程效率上看,这都是一次相当激进的迭代。
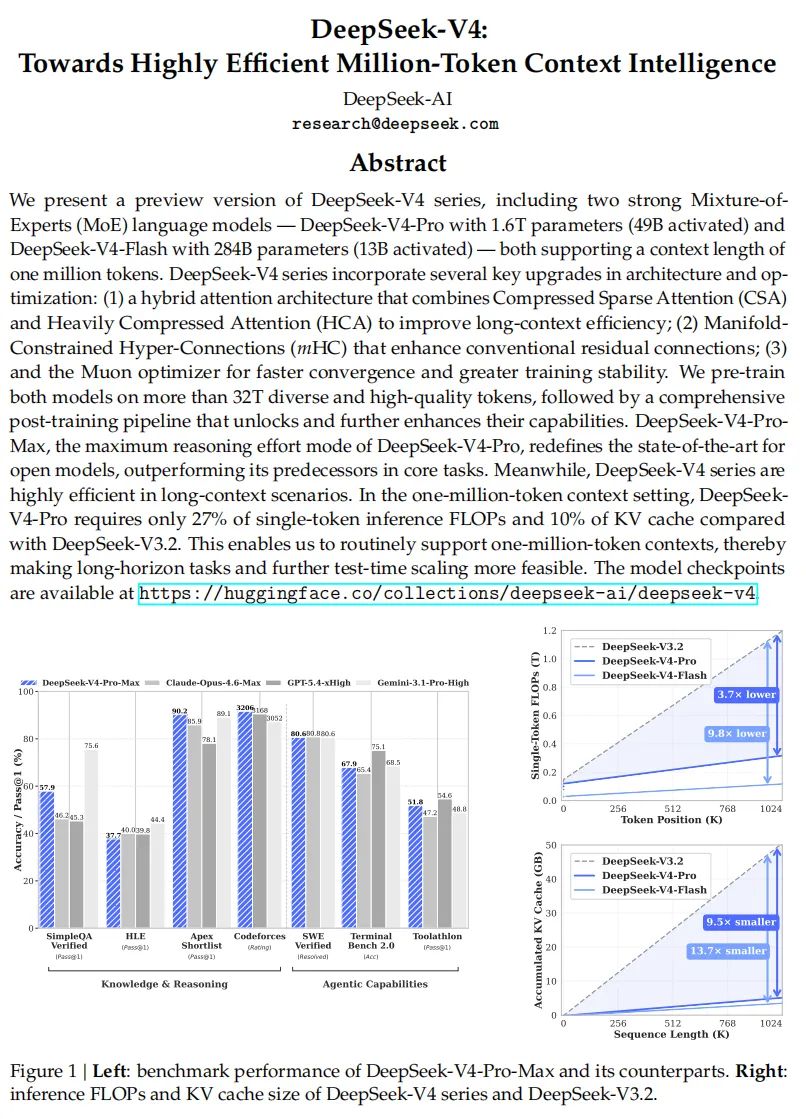
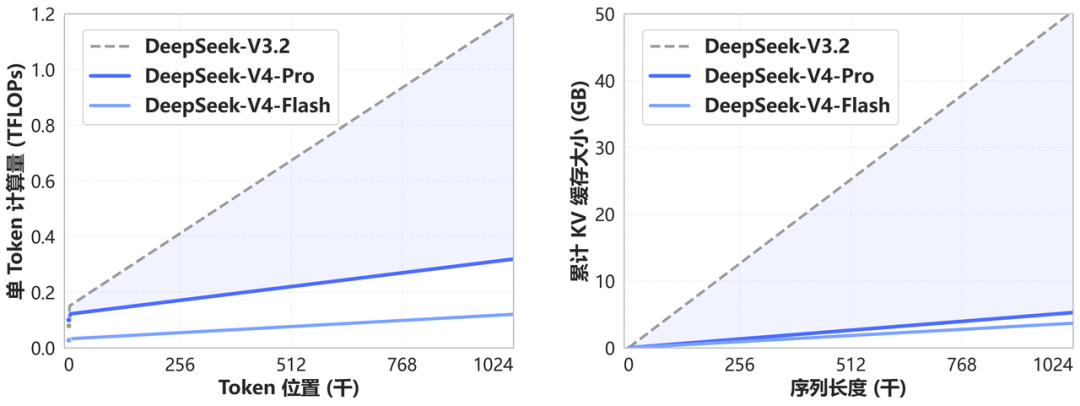
与以往不同的是,V4 的跃升并不只是“更强了”。它首次把百万 token 上下文作为默认能力交付给社区,同时把单 token 推理的计算量降到 V3.2 版本的 27%,KV 缓存仅为原来的十分之一。这意味着,超长文本处理不再只是实验室里的演示,而是开始走向实用、低成本。
硬件层面,DeepSeek 这次做了一个“跨生态”的全面适配——从训练到推理,整套流程已完整运行在华为昇腾 NPU 之上。同时,自研的细粒度专家并行方案 MegaMoE,把通信和计算交织成一条流水线,在英伟达 GPU 和昇腾 NPU 上分别实现了 1.50 到 1.73 倍的加速,延迟敏感场景下甚至可接近翻倍。其 CUDA 实现 MegaMoE2 也已开源,成为 DeepGEMM 工具包的一部分。
为了让碎片化的计算变得紧凑,团队用 TileLang 把大量零散的小算子融合成大型内核,调用开销从百微秒级骤降到 1 微秒以内,并借助 Z3 形式化验证器确保每次计算在任意批次位置下都给出完全一致的结果。这种“比特级可复现”的设计,对大型模型调试来说几乎是一种保命机制。此外,FP4 量化被部署在 MoE 专家权重和压缩稀疏注意力的 QK 路径上,让长上下文下的注意力分数计算进一步提速。
架构改动是这次长文本效率突破的关键。V4 仍然沿用 MoE 结构和多 token 预测,但注意力部分彻底重构,将压缩稀疏注意力与另一种高压缩稠密注意力组合成“混合注意力”,在保证信息利用的同时大幅缩减计算和存储开销。同时,残差连接被替换为“流形约束超连接”,以增强表达力,训练端则引入 Muon 优化器,收敛更快且更稳定。推理时,KV 缓存可部分下沉至磁盘,使得极长上下文的部署不会直接撑爆内存。
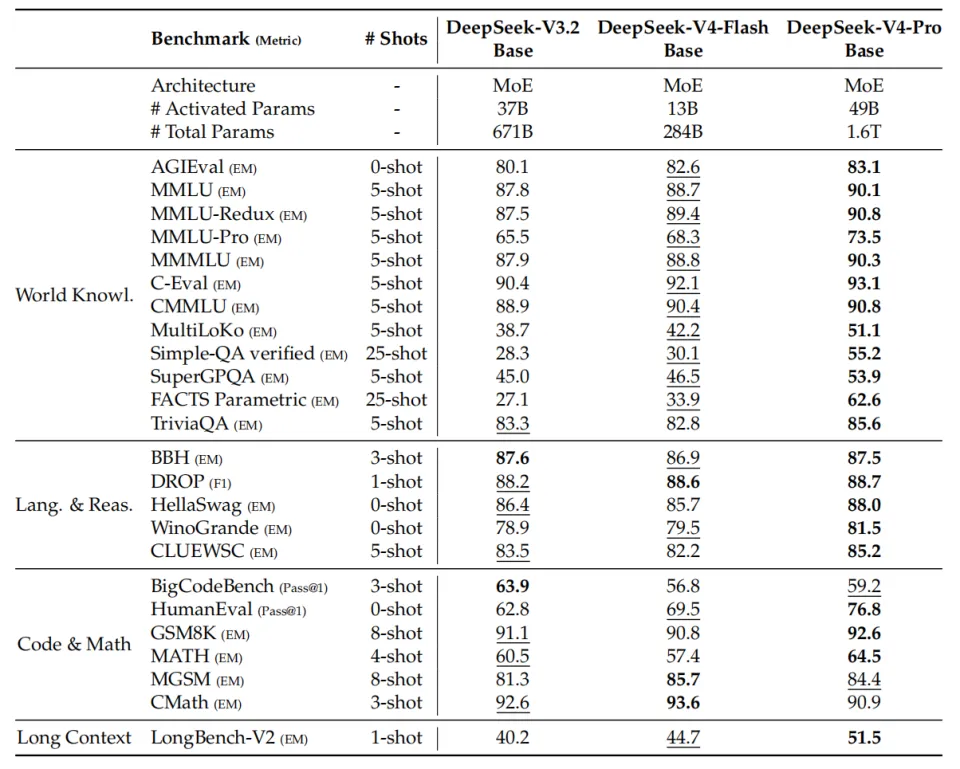
预训练数据的总量超过 32 万亿 token,并首度引入了“样本级注意力掩码”机制。网页数据经过严格过滤,剔除批量生成和模板化的低质内容;数学、编程仍是核心,中期还加入智能体数据;多语言语料扩充了各个文化中的长尾知识,而长文档部分则优先收录论文和技术报告。在这些基础上,V4-Flash 基础模型虽参数更少,却在世界知识和长上下文等任务中超越了 V3.2 基础模型;V4-Pro 基础版则几乎在所有基准上刷新了 DeepSeek 的记录。
后训练阶段的路线也出现了重要转变。先前的混合强化学习阶段被完全移除,取而代之的是“基于策略的蒸馏”。具体做法是,先为每个目标领域分别训练一个专家模型,经过监督微调和 GRPO 强化学习后,得到一群各有所长的“专才”。接下来,统一的学生模型开始自己采样并答题,过程中十多位专家老师在完整词表维度上通过逆向 KL 损失进行 logit 级对齐,以此实现专长的融合。这种全词表蒸馏让梯度更稳定,训练曲线也更容易控制。
与蒸馏策略相配套的,还有对长窗口场景下推理记录的精细管理。当模型处于工具调用环境中时,所有思考轨迹会跨轮次完整保留,让智能体在长时间任务中能够保持连贯的推理链;而在普通对话下,则仍会清除上一轮的推理内容,维持上下文的简洁。
同时Deepseek V4模型也针对 Claude Code 、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升。
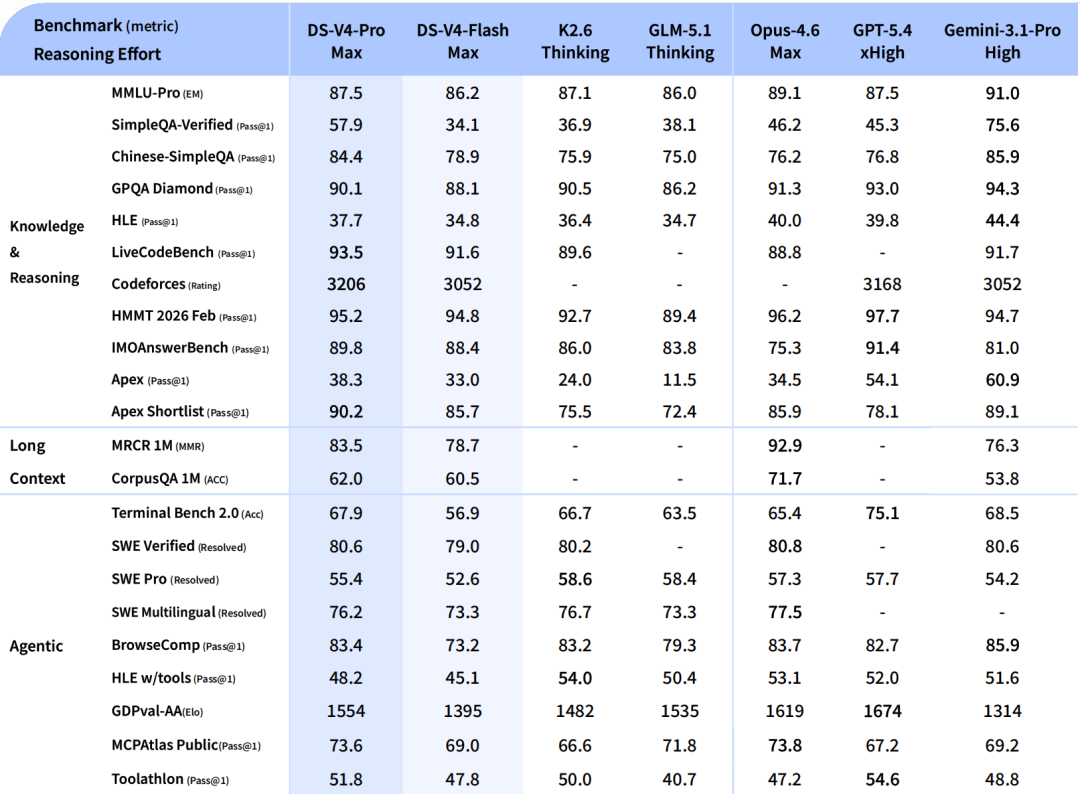
评测数据上,DeepSeek V4-Pro-Max 在知识、推理和代码能力上全线提升,综合表现已可对标 GPT-5.4、Claude Opus 4.6 等顶级闭源模型。其推理得分超过 GPT-5.2 和 Gemini 3.0 Pro,知识项略低于 Gemini 3.1 Pro。智能体能力与 Kimi K2.6、GLM-5.1 等领先开源模型持平,长上下文测试在学术基准上甚至超过了 Gemini 3.1 Pro。V4-Flash-Max 则在更低成本下提供了不俗的推理表现,展现出极高的性价比,在部分任务上接近 Pro 版本的水平。
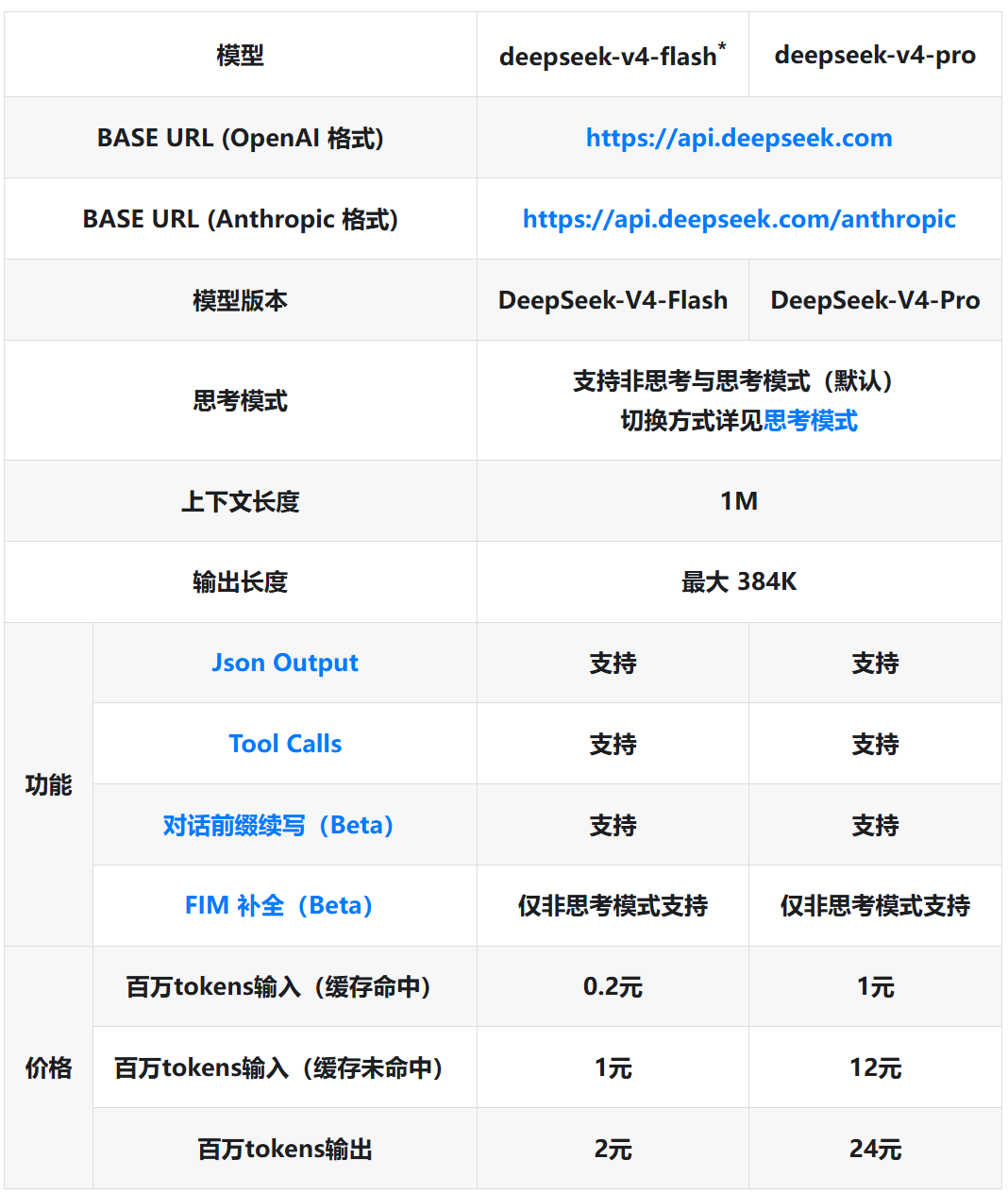
同时值得注意的是,这次Deepseek V4更新后仍然保持与ChatGPT、Claude等模型相对比非常便宜的定价。
其快速版本输入仅每百万Tokens 1元,输出仅每百万Tokens 2元,相较于ChatGPT,Claude等顶尖版本的模型,定价便宜了几十至数百元人民币。
但是也有技术报告坦诚指出,目前的架构仍偏复杂,Anticipatory Routing 和 SwiGLU Clamping 等稳定性机制的内在机理还有待进一步厘清。后续工作方向包括简化结构、提升训练稳定性、向更多稀疏化方向探索、缩短长上下文推理延迟,以及增强多轮智能体和多模态能力等。

整体来讲,开源的DeepSeek V4 把超长上下文的效率推到新高度,其综合能力极为强大,再一次拉近开源模型与闭源模型的距离。同时这次Deepseek将V4模型分为多个版本,如flash、pro、max、base等版本,可能也是转向商业化的又一步。